
2021. 4. 12. 19:30ㆍ논문 리뷰
Pre-trained word representations
- Pre-trained 된 word representation 자체가 downstream task들에 대한 key component가 된다
- A key component in many neural language understanding models
그렇다면 high quality representation이란 무엇이냐?
- Complex characteristics of word use (e.g. syntax and semantics) -> 구문분석, 의미분석 두분야에서 어떻게 사용되는지 모두 파악해야한다
- How these uses vary across linguistic contexts (i.e. to model polysemy) -> 언어학적인 contexts상에서 서로 다르게 사용될 때 해당되는 representation으로 잘 사용되어야 한다.

'눈' 이라는 단어가 있다고 가정해보자.
1. eye
2. snow
이렇게 다양하게 쓰일 수 있는데 이 단어의 embedding 될 때, 의미하는 바에 따라서 다르게 embedding되어야 한다는 것이다.
ELMo의 특징
- Each token is assigned a representation that is a fuction of the entire input sentence
- Use vectors derived from a bidirectional LSTM that is trained with a coupled language model (LM) objective on a large text corpus
- ELMo representations are deep in the sense that they are a function of all of the internal layers of the biLM -> bidirectional LSTM의 모든 internal layer에 해당하는 hidden vector들을 결합하여 특별한 층에 해당하는 것을 사용하는 것이 아니라 bidirectional LSTM이 학습이 되었을 때 나오는 아래의 그림과 같이 다양한 layer에서의 hidden vector들을 결합하여 사용한다

위쪽의 hidden vector들은 context-dependent aspect를 나타낸다 -> qustion and answering 같은 문장의 이해에 관련된 부분에서는 윗 vector들에 더 가중치를 크게 둠으로 사용할 수 있고,
아래쪽의 hidden vector들은 구문 분석에 해당하는 syntax analysis를 해야한다면 아래 vector들에 더 가중치를 크게 두고 결합하여 사용함으로써 유연하면서도 여러 task에 성능을 잘 내는 representation을 생성할 수 있다.
각 단어를 나타낼 때, 전체를 보고 embedding을 해주는데, 예를 들어 "Let's stick to improvisation in this skit" 라는 문장이 있을 때, improvisation을 예측한다고 하면,

ELMo 가 가지는 방식은 기본적인 구조는 Language Modeling이다 -> 지금까지 주어진 단어의 sequence들을 통해서 다음 단어를 예측하는 방식
ELMo가 하고자 하는 방식은 Biderectional 모델이다 -> forward 로도 학습하고 backward로도 학습을 한다

forward와 backward방향의 학습된 vector들을 같이 사용해줄 때는,
- 서로 대응되는 것끼리 concatenate를 해줘서 사용한다
- 특정한 task에 따라 concatenate한 vector들 간의 적절한 weighted sum을 통해 하나의 vector로 만들어준다
- 하나로 weighted sum 된 vector가 ELMo에 의해 만들어진 representation이 된다

위의 그림에 나오는 적절절한 weighted sum에 사용되는 S1, S2, S3는 downstream task가 무어냐에 따라 함께 학습이 되는 parameter이다
context 적으로 의미를 봐야하는 task라면 S1에 가중치를 둬서 살펴보게 하고, syntax 적으로 의미를 주로 봐줘야 한다면 S3에 가중치를 더 줘서 반영해서 하나의 vector로 만들기 때문에 유동적이라고 볼 수 있다
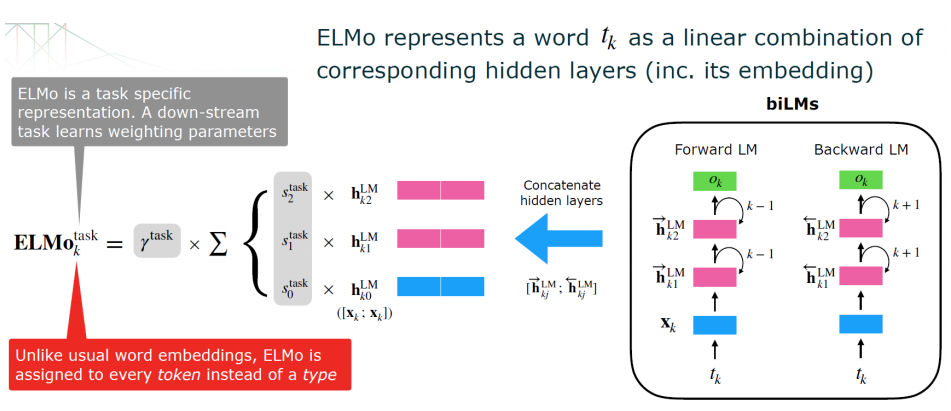
task에 specific한 가중치 (S0, S1, S2) 들을 학습을 시키겠다
앞에 붙은 감마의 경우는 task에 대한 scale factor로 볼 수 있다 -> 전체 weighted sum 된 ELMo의 pre-trained 된 vector를 얼마만큼 크게 사용하거나 줄이거나를 결정하는 요소
Bidirectional 학습을 자세히 살펴보자면,
N개의 sequence가 존재한다고 가정한다면, k번째 token을 예측하기 위해서 1부터 k-1까지의 token의 정보를 다 가지고 있다고 가정을 한다. 각각의 N개의 token sequence가 나타날 결합확률분포는 k는 1부터 마지막 단어까지 이전에 존재하는 모든 단어를 조건부로 삼아서 k번째 단어가 등장할 확률을 계산해준다음, 전부 곱해주는 것이 된다.

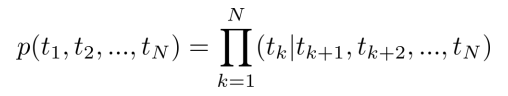
- $$X_k^{LM} : context-independent한 초기 embedding 값$$ -> L개의 layer를 가진 LSTM에 넣어주게 된다
- 각각의 position k에 대해서 $$\vec{h_{k, j}^{LM}} where j=1...L$$ hidden state들은 context-dependent한 representation이다
- 가장 윗단의 LSTM의 output $$\vec{h_{k, L}^{LM}}$$이 다음번 token을 예측하는데 사용이된다.
여기까지가 가장 기본적인 forward language model이 된다.
backward의 경우는 정반대로 수행을 해주게 된다.

forward language model의 likelihood와 backward language model의 likelihood 모두 최대화 해줘야 한다
이러한 Bidirectional Language Model이 학습이 되게 되면, 각각의 token k에 대해서 $$t_k$$ 각각의 token들에 대해서 2L+1 개의 representation을 얻을 수 있다. -> 단어의 embedding원본 + forward 방향의 L개 + backward 방향으로의 L개

이것들을 이용해서 최종적으로 downstream task를 해주기 위해 모든 레이어에 있는 vector들을 하나의 single vector로 collapse를 시켜준다 -> weight를 활용해서 weighted sum을 해준다는 이야기

$$h_{k,0}^{LM} = [x_k^{LM}:x_k^{LM}]$$ => input vector들이 다 forward와 backward의 concatenate이므로 사이즈를 맞춰주기 위해 두배로 늘려 표현한다
$$S_j^{task}$$ : 가중치들의 표현 -> 모든 weighted들은 0~1사이이며 합이 1이어야 한다
그렇다면 ELMo는 어떻게 사용할까?

ELMo의 성능 시험

수치보다는 다양한 task에 적용시켰다는 점에 초점을 두고 봐야한다.
이 정리는 youtu.be/zV8kIUwH32M
를 보고 정리한 내용입니다.
너무 잘 정리해주셔서 이해를 잘 할 수 있었습니다. 감사합니다.
참고 자료: github.com/pilsung-kang/text-analytics
pilsung-kang/Text-Analytics
Unstructured Data Analysis (Graduate) @Korea University - pilsung-kang/Text-Analytics
github.com
'논문 리뷰' 카테고리의 다른 글
| GPT-2 : Language Models are Unsupervised Multitask Learners (0) | 2021.04.15 |
|---|---|
| OpenAI GPT-1 : Improving Language Understanding by Generative Pre-training (0) | 2021.04.13 |
| Bert : Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2021.04.09 |
| Swin Transformer: Hierarchical Vision Transformer using shifted Windows (0) | 2021.04.01 |
| Video Transformer Network (0) | 2021.03.25 |