
2021. 3. 10. 19:45ㆍ논문 리뷰
Abstract
Siamese network는 unsupervised visual representation learning task를 수행하는데 있어 보편적인 구조로 자리매김하였다.
이 구조는 한 이미지로부터 augmentation된 2개의 이미지 사이의 similarity를 최대화 한다.
논문에서는 간단한 Siamese network를 통해
- negative sample pairs
- large batches
- momentum encoders
세가지 요소 없이 의미있는 representation을 추출해냈다.
하지만 Siamese network에는 collapsing 문제가 존재해왔고, 이 논문에서 진행한 실험에서는 stop-gradient가 collapsing을 막는데 중요한 역할을 한다는 것을 보여준다.
또한 제시한 "SimSiam" 방법으로 ImageNet과 downstream task에서 좋은 결과를 보여주었다.
Introduction
최근 un/self-supervised representation learning이 hot해지고 있으며 대부분 Siamese network형태를 포함하고 있다.
Simamese network란?
둘, 혹은 그 이상의 input을 넣고 weight sharing을 통해 대상을 비교해주는 역할을 한다. 이를 최근 방법들은 한 이미지로부터 augmentation한 두개의 이미지의 유사도를 최대화하는 방법으로 정의하고 있다.
하지만, Siamese Network에는 output이 constant로 붕괴한다는 문제점이 있었고, 이를 해결하기 위한 방법들로는,
- Contrastive learning, instantiated in SimCLR, repulses differnt images (negative pairs) while attracting the same image's two views (positive pairs).
- SwAV incorporates online clustering into Siamese networks.
- BYOL relies only on positive pairs but it does not collapse in case a momentum encoder is used.
이 논문에서는 위에서 언급한 방법들을 사용하지 않고도 간단하게 collapsing을 막는 방법을 제시하고자 한다. 모델은 negative pair나 momentum encoder를 사용하지 않고도 한 이미지로부터의 augmentation 된 두 이미지의 similarity를 최대화 할 수 있고 고질적인 문제인 large-batch training 대신 전형적인 batch size로 진행된다.

SimSiam은 간단해서 현재 존재하는 method들에도 적용하여 사용할 수 있는데, 이를 테면 BYOL에 적용을 한다면 "BYOL without the momentum encoder"처럼 표현할 수 있다.
Related Work
Siamese networks. The inputs to Siamese networks are from different images, and the comparability is determined by supervision
Contrastive learning. The core idea of contrastive learning is to attract the positive sample pairs and repulse the negative sample pairs.
Clustering. SwAV incorporates clustering into a Siamese network, by computing the assignment from one view and predicting it from another view. SwAV performs online clustering under a balanced partition contraint for each batch, which is solved by the Sinkhorn-Knopp transform.
BYOL. directly predicts the output of one view from another view. It is a Siamese network in which one branch is a momentum encoder.
Method

동작 방법은 의외로 간단하다.
위의 Psudocode 그대로 한 이미지로부터 augmented 된 view $x_1$와 $x_2$를 얻는다. 두 view들은 encoder network f consisting of a backbone ResNet 로 통과하게 되고 MLP함수 h에 의해 projection 된다.
encoder f는 두 뷰간의 weight를 sharing 하고 MLP head h는 한 view의 결과를 다른 한 view로 match 시켜간다.
p1 = h(f(x1))
p2 = h(f(x2)) 라고 했을 때, 둘 사이의 negative cosine similarity를 최적화 해준다


위의 loss는 각 이미지에 대한 loss이고 전체 loss는 모든 이미지들의 loss 평균이다.
이 work의 핷심은 stop-gradient인데 이는
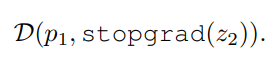
로 표현할 수 있으며 위의 Pseudocode를 보면 z=z.detach()해주는 부분을 볼 수 있다.
따라서 이를 적용해서 similarity를 구한 Loss 함수를

이렇게 정의해 줄 수 있다.
이렇게 되면 x2의 encoder의 경우 first term에서 z2로부터 어떠한 gradient도 받지 못한다. 하지만 second term에서는 p2에서 gradients를 얻게 된다.
Baseline settings.
- optimizer : use SGD for pre-training
- projection MLP : has BN applied to each fully-connected layer, including its output fc
- prediction MLP : has BN applied to its hidden fc layers. Its output fc does not have BN or ReLU.
backbone으로는 ResNet-50을 사용했다.
Experimental setup. 1000-class ImageNet training set에 대하여 label없이 unsupervised pre-training을 진행했다.
Empirical Study
Stop-gradient

위의 그림을 보면 stop-gradient를 했을 때와 안했을때의 차이를 분명하게 보여준다.
stop-gradient가 없으면 optimizer quickly finds a degenerated solution and reaches theminimum possible loss of -1. 또한 output의 collapse 되는 현상을 보였다.
Discussion. 이 논문에서는 실험을 통해 collapsing solutions 가 존재한다는 사실을 보였다. collapse는 minimum possible loss와 constant output을 보면 대략 알 수 있다.
Predictor
model은 MLP 함수 h를 제거 하면 작동하지 않는다. h는 identity mapping 과정이다.
사실 위의 Loss 함수를 보면 D(z1, z2)를 1/2 해준 결과 gradient와 같은 방향을 갖게 된다. h를 random initializaition으로 고정해놔도 제대로 동작하지 않는다.
그러나 제대로 동작하지 않는다고 collapsing 문제는 아니다. loss가 잘 떨어지지 않는다. 이말은 predictor h 가 representation에 대해 학습이 필요하다는 것이다.
또한 이 논문에서 고정된 learning rate를 갖는 h가 더 좋은 결과를 내는 것을 알아냈다.
이는 아마 위에서 언급한 내용처럼 최근의 representation들에 대해 학습을 하게 되는 경우에는 굳이 lr을 reducing할 필요가 없는 것이다.
Batch Size
기존의 work들은 batch size를 크게하여 batch size내 비교를 통해 similarity를 측정했지만, SimSiam의 경우 다양한 batch size를 적용해도 전부 다 잘 동작하는 것을 볼 수 있었다.
Batch Normalization
MLP heads에서 BNormalization을 제거했을 때 collapse는 일어나지 않았고 hidden layer에 적용했을 경우 정확도가 올라가는 것을 확인 할 수 있었다. 오히려 output에 BN을 적용할 경우 collapsing이 일어나는 것을 확인할 수 있었다.
요약 하자면, 실험을 통해 이 논문에서는 BN이 supervised learning 에서처럼 적절히 잘 쓰이면 optimization에 도움을 준다는 것을 발견했다. 하지만 어떻게 BN이 collapsing을 방지하는지는 증거가 없었다.
Similarity Function
D function을 cosine similarity -> cross-entropy similarity로 바꾸어보았다.
D(p1, z2) = -softmax(z2) x logsoftmax(p1)
여기서 softmax는 channel dimension으로 해주게 되고 softmax를 통해 나온 결과는 pseudo-categories에 어디에 속할지에 대한 각각의 확률을 나타내게 된다.
similarity 함수를 바꿨을 때의 결과는

이와 같이 나오게 되고, 이를 통해 cross-entropy도 collapsing없이 reasonable한 결과를 얻을 수 있다는 것을 알 수 있다. 이는 collapsing prevention behavior가 cosine similarity에만 영향을 받지 않는다 라는 것을 보여주는 결과 이기도 하다.
Symmetrization
SimSiam이 collapsing을 방지하는 것은 symmetrization에 의해 그런 것이 아니라는 사실을 발견했다.
asymmetric 한 variant와 비교했을때 크게 차이가 나지 않았다. Symmetrization 구조는 정확도 발전에는 기여하지만 collapsing prevent와는 관련이 있지 않다.
Summary
위의 경우들을 보아 SimSiam이 collapsing 없이 좋은 결과를 낸다는 것을 확인할 수 있었다.
Batch size, batch normalization, simlilarity function, and symmetrization 이러한 요소들은 정확도에는 영향을 끼쳤지만 이들이 collapsing을 막는다는 증거가 없었다. 이는 stop-gradient이 필수적인 요소를 했다고 볼 수 있다.
Conclusion
뒤의 내용들은 하나씩 짚어가며 stop-gradient가 왜 collapsing prevent에 영향을 끼쳤는지에 대한 가설 및 증명이다. 내가 하나씩 다 이해하기가 벅차 일단 위의 내용까지만 정리하며 다음번에 더 내용을 추가하여 업로드 하도록 해야겠다 :(
'논문 리뷰' 카테고리의 다른 글
| ELMo : Embeddings from Language Models (0) | 2021.04.12 |
|---|---|
| Bert : Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2021.04.09 |
| Swin Transformer: Hierarchical Vision Transformer using shifted Windows (0) | 2021.04.01 |
| Video Transformer Network (0) | 2021.03.25 |
| ContraGAN: Contrastive Learning for Conditional Image Generation 논문 리뷰 (0) | 2021.03.02 |